You can convert your PDF to Excel, CSV, XML or HTML with Python using the PDFTables API. Our API will enable you to convert PDFs without uploading each one manually.
In this tutorial, I'll be showing you how to get the library set up on your local machine and then use it to convert PDF to Excel, with Python.
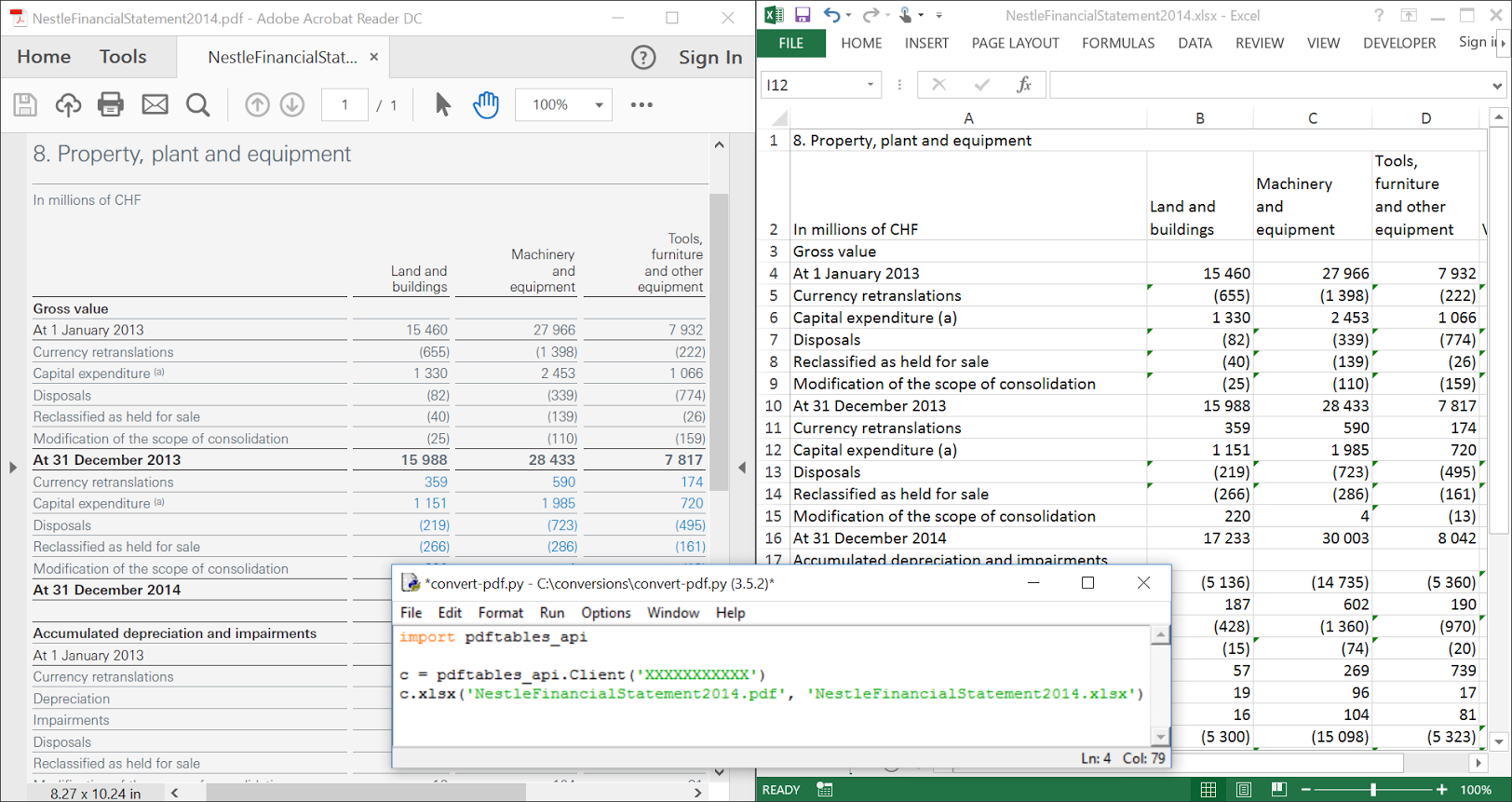
Here's an example of a PDF that I've converted with the library. In order to properly test the library, make sure you have a PDF handy!
If you haven't already, install Anaconda on your machine from Anaconda website. You can use either Python 3.6.x or 2.7.x, as the PDFTables API works with both. Downloading Anaconda means that pip will also be installed. Pip gives a simple way to install the PDFTables API Python package.
For this tutorial, I'll be using the Windows Python IDLE Shell, but the instructions are almost identical for Linux and Mac.
In your terminal/command line, install the PDFTables Python library with:
pip install git+https://github.com/pdftables/python-pdftables-api.git
If git is not recognised, download it here. Then, run the above command again.
Or if you'd prefer to install it manually, you can download it from python-pdftables-api then install it with:
python setup.py install
Create a new Python script then add the following code:
import pdftables_api c = pdftables_api.Client('my-api-key') c.xlsx('input.pdf', 'output') #replace c.xlsx with c.csv to convert to CSV #replace c.xlsx with c.xml to convert to XML #replace c.xlsx with c.html to convert to HTML
Now, you'll need to make the following changes to the script:
Now, save your finished script as convert-pdf.py in the same directory as the PDF document you'd like to convert.
If you don’t understand the script above, see the script overview section.
Open your command line/terminal and change your directory (e.g. cd C:/Users/Bob ) to the folder you saved your convert-pdf.py script and PDF in, then run the following command:
python convert-pdf.py
To find your converted spreadsheet, navigate to the folder in your file explorer and hey presto, you've converted a PDF to Excel or CSV with Python!
The first line is simply importing the PDFTables API toolset, so that Python knows what to do when certain actions are called. The second line is calling the PDFTables API with your unique API key. This means here at PDFTables we know which account is using the API and how many PDF pages are available. Finally, the third line is telling Python to convert the file with name input.pdf to xlsx and also what you would like it to be called upon output: output . To convert to CSV, XML or HTML simply change c.xlsx to be c.csv , c.xml or c.html respectively.
Check out our blog post here.
Love PDFTables? Leave us a review on our Trustpilot page!